从LM算法求解最小二乘到DeepLM
最小二乘问题
最小二乘是一种寻找最佳拟合的数学方法,例如有一些数据点散布在坐标系中,希望寻找一条线能够穿过这些点,并且使得所有点到这条线的垂直距离最短。
具体来说,最小二乘法的核心思想分为以下几个步骤:
- 计算每个数据点到这条线的垂直距离
- 把这些距离平方后(防止正负抵消)相加
- 找到一条使距离平方和最小的线
[fig 散点和线]
求解最小二乘问题
从最基础的例子开始,假设要拟合一条直线,也就是线性最小二乘问题 $$ y=ax+b $$ $n$个数据点的误差函数为 $$ L(a,b)=\sum_1^n(y_i-(ax_i+b))^2 $$
由于这个误差函数是一个凸二次函数,可以通过求$L$对$a$和$b$的偏导并令其等于0来求最小误差:
$$ \partial L/ \partial a=-2\sum_1^n(y_i-ax_i-b)x_i=0 \\ \partial L/ \partial b=-2\sum_1^n(y_i-ax_i-b)=0 $$求解以上方程组即可得到最优的参数a和b,这个方程组称为正规方程
在实际计算中,将多个点带入公式(1), $$ x_1a+b=y_1\\ x_2a+b=y_2\\ \cdots\\ x_na+b=y_n $$ 可以表示为矩阵形式 $$ \begin{bmatrix} x_1&1\\ x_2&1\\ \cdots&\cdots\\ x_n&1 \end{bmatrix} \begin{bmatrix} a\\ b \end{bmatrix}= \begin{bmatrix} y_1\\ y_2\\ \cdots\\ y_n \end{bmatrix} $$
简写为 $$ \mathbf{X}\bf{\beta}=\mathbf{y} $$ 这个方程组一般没有精确解(有精确解的情况下,所有的点都刚好在直线上),所以要通过最小二乘法求最优的a和b,根据公式(2),误差函数为: $$ L(\beta)=(\mathbf{X}\bf{\beta}-\mathbf{y})^\top(\mathbf{X}\bf{\beta}-\mathbf{y}) $$ 通过求导得到正规方程 $$ \mathbf{X}^\top\mathbf{X}\bf{\beta}=\mathbf{X}^\top\mathbf{y} $$ 所以最终的解为 $$ \bf{\beta}=(\mathbf{X}^\top\mathbf{X})^{-1}\mathbf{X}^\top\mathbf{y} $$ 更加复杂的情况下,需要拟合的点可能不是一条直线,而是曲线,也就是非线性最小二乘问题 $$ y=f(x,\beta) $$ 其中$f$为非线性函数
非线性问题没有办法用正规方程求解,因为非线性问题的正规函数也是非线性的,例如,要求解指数函数的最小二乘问题 $$ y=\beta_1exp(\beta_2x) $$ 目标函数为: $$ L(\beta_1,\beta_2)=\sum(y_i-\beta_1exp(\beta_2x_i))^2 $$ 求偏导得 $$ \partial L/\partial\beta_1=-2\sum(y_i-\beta_1exp(\beta_2x_i))exp(\beta_2x_i)=0\\ \partial L/\partial\beta_2=-2\sum(y_i-\beta_1exp(\beta_2x_i))\beta_1x_iexp(\beta_2x_i)=0 $$ 得到的非线性的正规函数没有办法直接求解,因此需要换一种方法,通过泰勒展开用线性近似代替原来的非线性函数
假设当前是第k次迭代,表示为上标$(k)$
公式(12)所表示的指数函数最小二乘目标函数,在点$\beta_1^{(k)},\beta_2^{(k)}$处的一阶泰勒展开为 $$ f(x;\beta)\approx f(x;\beta^{(k)})+(\partial f/\partial \beta_1)(\beta_1-\beta_1^{(k)})+(\partial f/\partial\beta_2)(\beta_2-\beta_2^{(k)}) $$ 其中$f(x;\beta^{(k)})=\beta_1^{(k)}exp(\beta_2^{(k)}x)$,$\partial f/\partial\beta_1=exp(\beta_2^{(k)}x)$,$\partial f/\partial\beta_2=\beta_1^{(k)}xexp(\beta_2^{(k)}x)$,代入得 $$ f(x_i;\beta) \approx \beta_1^{(k)}exp(\beta_2^{(k)}x_i) + exp(\beta_2^{(k)}x_i)(\beta_1-\beta_1^{(k)}) + \beta_1^{(k)}x_iexp(\beta_2^{(k)}x_i)(\beta_2-\beta_2^{(k)}) $$ 代入残差表达式$r_i=y_i-\beta_1exp(\beta_2x_i)$,得 $$ r_i = y_i - [\beta_1^{(k)}exp(\beta_2^{(k)}x_i) + exp(\beta_2^{(k)}x_i)(\beta_1-\beta_1^{(k)}) + \beta_1^{(k)}x_iexp(\beta_2^{(k)}x_i)(\beta_2-\beta_2^{(k)})] $$ 将参数的差记为增量的形式 $$ \Delta\beta_1 = \beta_1-\beta_1^{(k)}\\ \Delta\beta_2 = \beta_2-\beta_2^{(k)} $$ 整理后得到 $$ r_i = y_i - \beta_1^{(k)}exp(\beta_2^{(k)}x_i) - exp(\beta_2^{(k)}x_i)\Delta\beta_1 - \beta_1^{(k)}x_iexp(\beta_2^{(k)}x_i)\Delta\beta_2 $$
$$ r_i = r_i^{(k)} - [exp(\beta_2^{(k)}x_i)\Delta\beta_1 + \beta_1^{(k)}x_iexp(\beta_2^{(k)}x_i)\Delta\beta_2] $$记Jacobian矩阵的第i行为: $$ J_i = [-exp(\beta_2^{(k)}x_i), -\beta_1^{(k)}x_iexp(\beta_2^{(k)}x_i)] $$ 参数的增量为: $$ \Delta\beta = [\Delta\beta_1, \Delta\beta_2]^T $$ 则可以写成矩阵形式: $$ \begin{bmatrix} r_1 \\ r_2 \\ \vdots \\ r_n \end{bmatrix} \approx \begin{bmatrix} r_1^{(k)} \\ r_2^{(k)} \\ \vdots \\ r_n^{(k)} \end{bmatrix}- \begin{bmatrix} exp(\beta_2^{(k)}x_1) & \beta_1^{(k)}x_1exp(\beta_2^{(k)}x_1) \\ exp(\beta_2^{(k)}x_2) & \beta_1^{(k)}x_2exp(\beta_2^{(k)}x_2) \\ \vdots & \vdots \\ exp(\beta_2^{(k)}x_n) & \beta_1^{(k)}x_nexp(\beta_2^{(k)}x_n) \end{bmatrix} \begin{bmatrix} \Delta\beta_1 \\ \Delta\beta_2 \end{bmatrix} $$ 简写为: $$ r \approx r^{(k)} - J\Delta\beta $$ 此时通过泰勒展开的线性化,原本的最小二乘问题变为: $$ \min_{\Delta\beta} \|r^{(k)} - J\Delta\beta\|^2 $$ 由非线性最小二乘问题,转换成了线性最小二乘问题,即可通过求解正规方程的方式求解,正规方程为: $$ (J^TJ)\Delta\beta = J^Tr^{(k)} $$ 其中$r_i^{(k)} = y_i - \beta_1^{(k)}exp(\beta_2^{(k)}x_i)$,解得: $$ \Delta\beta = (J^TJ)^{-1}J^Tr^{(k)} $$ 由于泰勒展开只是在当前点$\beta^{(k)}$附近的局部近似,只在$\beta^{(k)}$附近具有好的近似效果,因此,只能在当前点的附近使用,如果直接更新参数 $$ \beta^{(k+1)} = \beta^{(k)} + \Delta\beta $$ 则违反了只能在当前点附近使用的规则,因此,需要使用一个步长因子来控制更新的方式,熟悉梯度下降的同学应该对步长这个概念不陌生,添加步长后的更新方式: $$ \beta^{(k+1)} = \beta^{(k)} + \alpha\Delta\beta $$ 其中$\alpha$为步长因子,$0<\alpha<1$
在更新参数$\beta$后,再重新从公式(25)开始计算新的参数更新量,经过多次迭代后得到一个较为准确的解
Levenberg-Marquardt方法
Levenberg-Marquardt(LM)方法中,修改了公式(25)中的正规方程,修改后的方程为: $$ (J^TJ + \lambda I)\Delta\beta = J^Tr^{(k)} $$ 多了一个阻尼参数$\lambda$,$I$为单位矩阵
当$\lambda$很大时,$\lambda I$项占主导地位,因此公式(29)可以近似为: $$ \lambda I\Delta\beta \approx J^Tr^{(k)} $$ 此时的解为: $$ \Delta\beta \approx \frac{1}{\lambda}J^Tr^{(k)} $$ 目标函数(12)关于参数$\beta$的梯度为 $$ \nabla L = \frac{\partial L}{\partial \beta} = -2\sum_i r_i\frac{\partial f}{\partial \beta} = -2J^Tr $$ 而公式(31)可以写为: $$ \Delta\beta \approx -\frac{1}{2\lambda}(-2J^Tr^{(k)}) = -\frac{1}{2\lambda}\nabla L $$ 这时的形式符合梯度下降: $$ \beta^{(k+1)} = \beta^{(k)} - \alpha\nabla L $$ 可以将公式(33)看做步长为$1/2\lambda$的梯度下降,所以在$\lambda$很大时,LM方法类似于梯度下降
当$\lambda$很小时,$J^TJ$占主导地位 $$ J^TJ\Delta\beta = J^Tr^{(k)} $$
$$ \Delta\beta = (J^TJ)^{-1}J^Tr^{(k)} $$此时的更新方程实际上就是Gauss-Newton方法的更新方程,在这里不赘述
总结来说就是,当$\lambda$很大时,步长与$\lambda$成反比,下降方向通过一阶导数确定,接近最速下降方向 $$ \|\Delta\beta\| \approx \frac{\|J^Tr\|}{\lambda} $$ 当$\lambda$很小时,步长由二阶导数的近似$(J^TJ)^{-1}$确定 $$ \|\Delta\beta\| \approx \|(J^TJ)^{-1}J^Tr\| $$ 在实际的计算中,初始计算时通常使用较大的$\lambda$,随着迭代的进行,逐渐减小$\lambda$,可以让计算过程始终保持稳定
LM算法的变体
LM算法中,最小二乘问题的正规方程写作: $$ (J^\top J + \lambda I)\Delta\beta = J^\top r^{(k)} $$ 其中每个参数的阻尼项$\lambda$都是相同的,但是在实际情况中,不同的参数项可能会具有尺度差异,例如$\Delta\beta = [\Delta\beta_1, \Delta\beta_2]^T$中,$\Delta\beta_1$可能是10000,$\Delta\beta_2$可能是1,这种情况下,相同的阻尼值对于不同参数项的影响显然是不同的。因此,一个更好的方法是根据不同参数的数值大小提供不同程度的阻尼。
修改以上正规方程为: $$ (J^\top J + \lambda D^\top D)\Delta\beta = J^\top r^{(k)} $$ 其中$D=\sqrt {diag(J^\top J)}$,$D$由$J^\top J$的对角元素构造,Jacobian矩阵$J$的形式为: $$ J=\begin{bmatrix} \partial r_1/\partial x_1 & \partial r_1/\partial x_2 & \cdots \partial r_1/\partial x_n\\ \partial r_2/\partial x_1 & \partial r_2/\partial x_2 & \cdots \partial r_2/\partial x_n\\ \cdots\\ \partial r_m/\partial x_1 & \partial r_m/\partial x_2 & \cdots \partial r_m/\partial x_n \end{bmatrix} $$
$$ J^TJ=\begin{bmatrix} \sum_{i=1}^m \frac{\partial r_i}{\partial x_1}\frac{\partial r_i}{\partial x_1} & \sum_{i=1}^m \frac{\partial r_i}{\partial x_1}\frac{\partial r_i}{\partial x_2} & \cdots & \sum_{i=1}^m \frac{\partial r_i}{\partial x_1}\frac{\partial r_i}{\partial x_n}\\ \sum_{i=1}^m \frac{\partial r_i}{\partial x_2}\frac{\partial r_i}{\partial x_1} & \sum_{i=1}^m \frac{\partial r_i}{\partial x_2}\frac{\partial r_i}{\partial x_2} & \cdots & \sum_{i=1}^m \frac{\partial r_i}{\partial x_2}\frac{\partial r_i}{\partial x_n}\\ \vdots & \vdots & \ddots & \vdots\\ \sum_{i=1}^m \frac{\partial r_i}{\partial x_n}\frac{\partial r_i}{\partial x_1} & \sum_{i=1}^m \frac{\partial r_i}{\partial x_n}\frac{\partial r_i}{\partial x_2} & \cdots & \sum_{i=1}^m \frac{\partial r_i}{\partial x_n}\frac{\partial r_i}{\partial x_n} \end{bmatrix} $$$$ D = \begin{bmatrix} \sqrt{\sum\limits_{k=1}^m \left( \frac{\partial r_k}{\partial x_1} \right)^2} & 0 & \cdots & 0 \\ 0 & \sqrt{\sum\limits_{k=1}^m \left( \frac{\partial r_k}{\partial x_2} \right)^2} & \cdots & 0 \\ \vdots & \vdots & \ddots & \vdots \\ 0 & 0 & \cdots & \sqrt{\sum\limits_{k=1}^m \left( \frac{\partial r_k}{\partial x_n} \right)^2} \end{bmatrix} $$假设用$d_i=D_{i,i}$表示矩阵$D$中对角线上的值,可以看到$d_1$是所有残差项对于$x_1$偏导数的平方和开根号,如果$x_1$对于所有残差的偏导数较大(此时$d_1$较大),说明$x_1$对于残差的影响较大,因此会收到更大的阻尼。可以理解为,如果某个参数对于残差的影响更大,则在更新这个参数时就会更加谨慎。
DeepLM
Huang J, Huang S, Sun M. Deeplm: Large-scale nonlinear least squares on deep learning frameworks using stochastic domain decomposition//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021: 10308-10317.
这篇文章想要解决的问题是用深度学习求解大规模非线性最小二乘问题。
深度学习框架大部分都实现了反向传播,也就是拥有求微分的能力。而根据公式(2)(3),LM算法在每次迭代计算$\Delta b$时,实际上需要计算的也是微分(Jacobian矩阵)。只不过深度学习的反向传播需要计算的是损失函数对于变量的微分,每次反向传播只需要一次计算来得到损失函数对于所有变量的微分,而非线性最小二乘问题每次迭代需要计算多个残差函数$r$对于变量的微分,可以理解为需要每一轮需要计算多次反向传播计算。
而DeepLM的作者想要解决的问题就是如何在一次计算中完成所有的微分计算,让非线性最小二乘问题能够利用深度学习计算框架求解。
残差索引
对于每次迭代需要多次“反向传播”的问题,作者的对策是通过相加把多个残差函数组成一个损失函数,这样就可以通过计算损失函数的反向传播来一次性计算所有残差函数对相关变量的微分,如下图所示
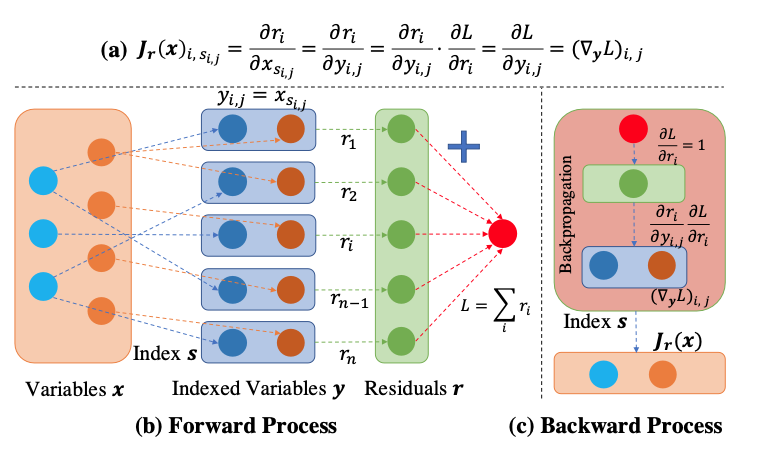
简单将所有残差项相加的计算公式虽然能够一次性得到所有的微分项,但是计算量要比普通的反向传播大n倍(n为残差项的数量),因此使用了一种类似查表的方法来减少计算量。在每次残差的计算过程中,每个残差项不一定与所有的变量都相关,例如文章中用作示例的Bundle Adjustment问题。
这个问题简单来说就是,在一个三维空间中,有多个需要观察的点和多个相机,每个点被一个相机观察时,观察值和这个点实际的投影值会产生一个误差,但是,由于遮挡的原因,并非每个相机都能看到所有的点,对于每个相机来说,有些点是不可见的,因此,对于一个相机来说,不可见的点(变量)并不包含在残差项中。如果想要降低计算量,在计算偏导数中,不要计算每个残差中与残差计算无关的点即可。
作者给出的方法是利用一个中间变量$y_{i,j}=x_{s_{i,j}}$,$y$可以理解为去掉不需要计算的变量后的$x$,两个下标中$i$是残差的索引,$j$是与第$i$个残差函数相关的第$j$个变量。相当于经过了一次查表去掉了减少了需要计算的残差数量。
在反向传播后,再根据下标关系将微分拼成Jacobian矩阵即可。
随机域分解
尽管通过索引降低了计算量,对于大规模问题来说每一次需要计算的微分还是太多了,会导致内存爆炸,因此需要将大问题分解为小问题来计算。
构建一个图$G=
举个栗子
有四个残差函数r1 依赖变量 {x1, x2, x3}
r2 依赖变量 {x2, x4, x5}
r3 依赖变量 {x3, x5, x6}
r4 依赖变量 {x6, x7, x8}
假设分了三个簇
Separators:{x2, x3, x6}
Block 1:{x1, x4, x5}
Block 2:{x7, x8}
确保:每个残差函数的变量要么都在同一个block内,要么包含至少一个separators的变量
这样分解可以确保每个block中的变量都只包含于一个残差函数中,就把全局问题分为了几个包含部分变量的局部问题,每次只需要优化一个局部问题即可。
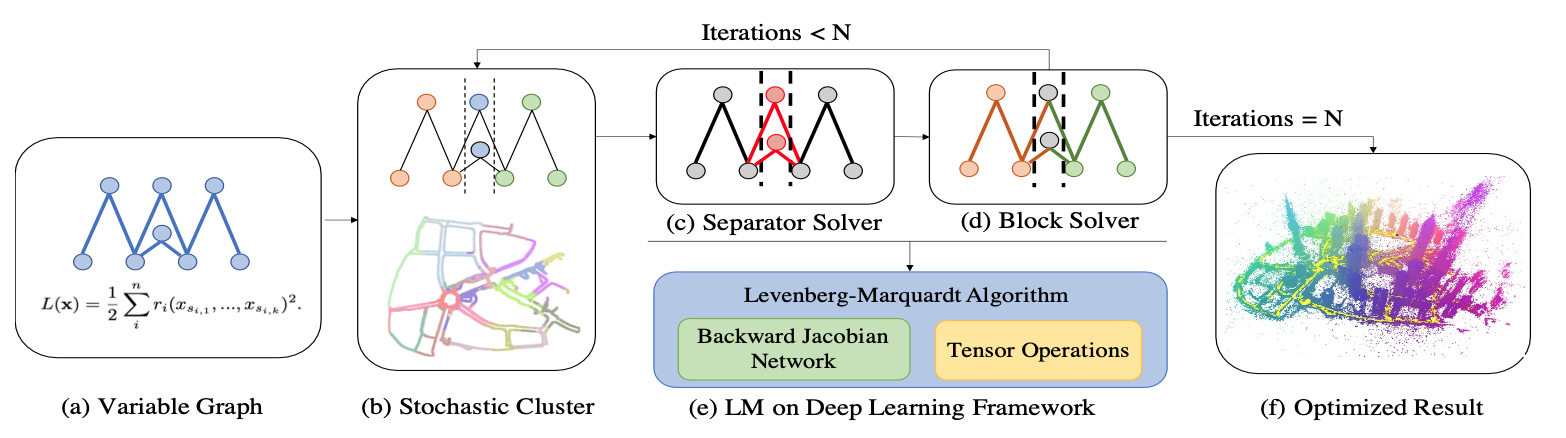
在计算流程中,先优化separator部分,然后优化block部分,由于block之间互相是没有直接联系的,因此多个block可以同时进行优化(并行)。
由于separator变量收敛比较慢,因此在训练过程中,需要随机进行多次聚类,使得separator和block中的变量在训练过程中进行交换,以此均衡收敛速度。
聚类的方式是进行基于模块度的随机贪婪,一开始将每个变量作为一个独立的簇,然后按照公式(6)计算两个簇的合并概率 $$ \operatorname{Prob}\left(N_x \cup N_y\right)=\frac{\exp \left(\beta \Delta Q\left(N_x, N_y\right)\right)}{\sum_i \sum_j \exp \left(\beta \Delta Q\left(N_i, N_j\right)\right)} $$ 其中$\operatorname{Prob}\left(N_x \cup N_y\right)$是合并两个簇的概率,$\beta$是可调节的参数,值越大越倾向于最优合并,越小随机性越强,$\Delta Q$是合并后模块度增加量,模块度$Q$定义为图中一个簇边的数量。在合并后簇的大小超过预设的阈值后停止。在聚类完成后,对于连接不同簇的边,随机选择一个端点加入separator,通过加入随机性可以使得每次separator中的变量有所变化,通过贪心合并使得separator包含的变量最少(block越大,簇越少,separator中变量越少)。